
In brief
- Microsoft released two different modes that pair GPT and Claude to increase the quality of AI research.
- Critique makes the models collaborate, whereas Council makes them work in parallel while a third judge finds the discrepancies.
- This two-model workflow fixes hallucinations, weak citations, and other problems associated with mono-model AI research.
Deep research AI has been one of the hottest arms races in tech this year. Google announced its research agent for Gemini in December 2024, OpenAI released its own research agent in February 2025, xAI followed suit, Perplexity doubled down, and Anthropic’s Claude built a loyal following among professionals who need detailed, cited answers, introducing its agent in April of last year.
Every company has been trying to convince you that their single AI model is the smartest researcher in the room. Microsoft just said: Why pick one?
The company announced two new features on Monday for Copilot’s Researcher tool—called Critique and Council—that put OpenAI’s GPT and Anthropic’s Claude to work on the same research task in sequence. The result, according to Microsoft’s testing against an industry benchmark, scores higher than every system included in that test, including models from the top AI companies.
Introducing Critique, a new multi-model deep research system in M365 Copilot.
You can use multiple models together to generate optimal responses and reports. pic.twitter.com/m4RlQmCKzs
— Satya Nadella (@satyanadella) March 30, 2026
“Critique is a new multi model deep research system designed for complex research tasks. It separates generation from evaluation and utilizes a combination of models from Frontier labs, including Anthropic and OpenAI,” Microsoft explains. “One model leads the generation phase, planning the task, iterating through retrieval, and producing an initial draft, while a second model focuses on review and refinement, acting as an expert reviewer before the final report is produced.”
Here’s the basic problem Critique is designed to fix: Every AI research tool today works the same way. You ask a question, one model plans a search, scours sources, writes a report, and hands it back to you. That single model is doing everything with no one checking its work.
This can end up with some hallucinations slipping in, some errors in citations, fake or inaccurate claims, etc.
Critique breaks that workflow in two. GPT handles the first phase—it plans the research, pulls sources, and writes an initial draft. Then Claude steps in as a strict editor, reviewing the report for factual accuracy, citation quality, and whether the answer actually addressed what was asked. Only after that review does the final report reach the user. Microsoft says the roles can eventually run in the opposite direction too, with Claude drafting and GPT critiquing, though for now GPT goes first.
On the DRACO benchmark—a standardized test covering 100 complex research tasks across 10 domains including medicine, law, and technology—Copilot with Critique scored 57.4. points with Anthropic’s Claude Opus 4.6 by itself hitting 42.7. Microsoft’s combined system beats the next best result by nearly 14%.
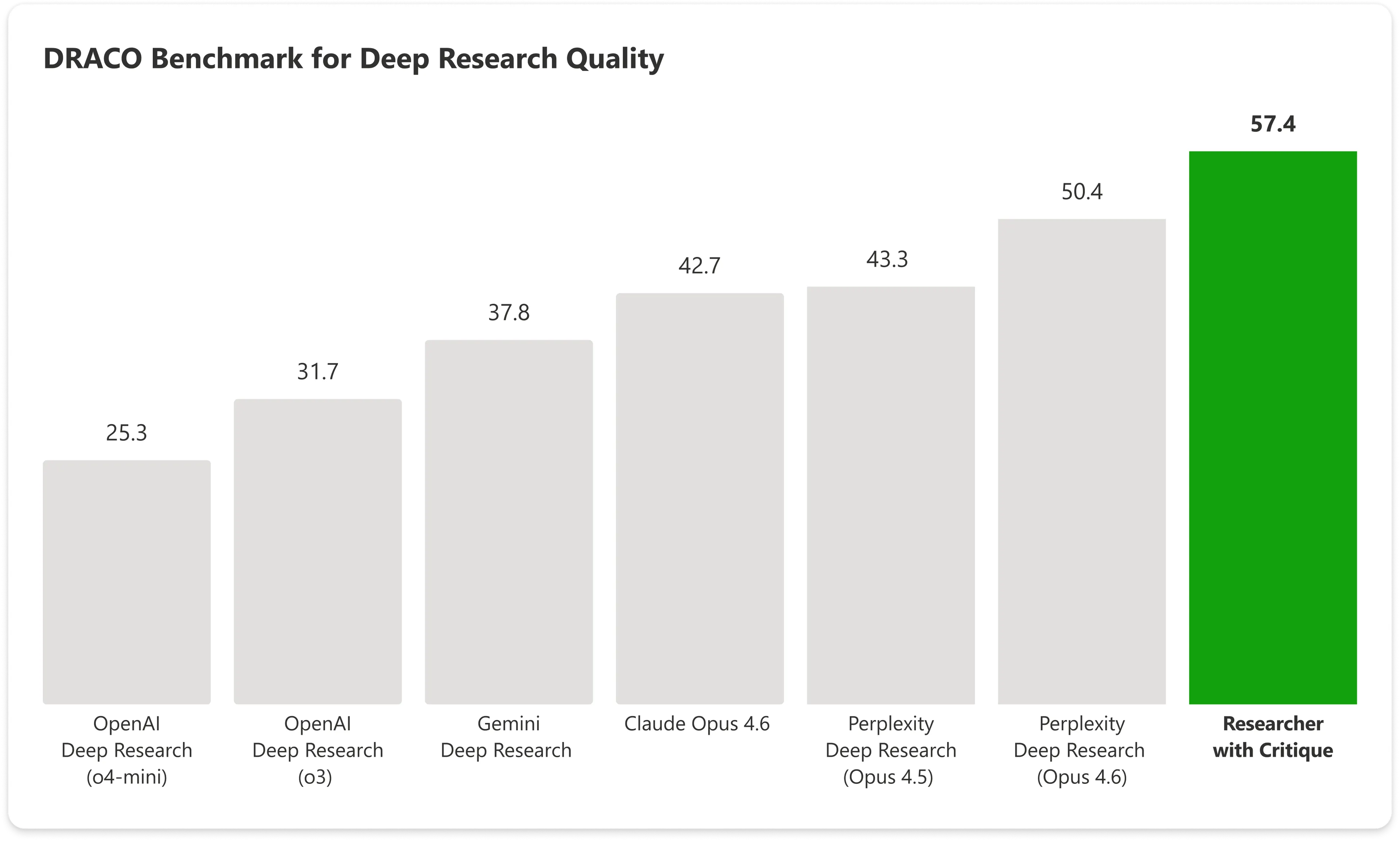
The biggest gains showed up in breadth of analysis and presentation quality, with factual accuracy also posting a significant improvement.
The second feature, Council, takes a different approach to the same problem. Instead of having one model review the other’s work, Council runs GPT and Claude simultaneously and puts their full reports side by side. A third “judge” model then reads both and writes a summary explaining where the two AIs agreed, where they diverged, and what unique angles each one caught that the other missed. Comparing AI research tools manually has been something users have had to do themselves until now.
In Critique, the models essentially collaborate with each other while in Council the models compete against each other.
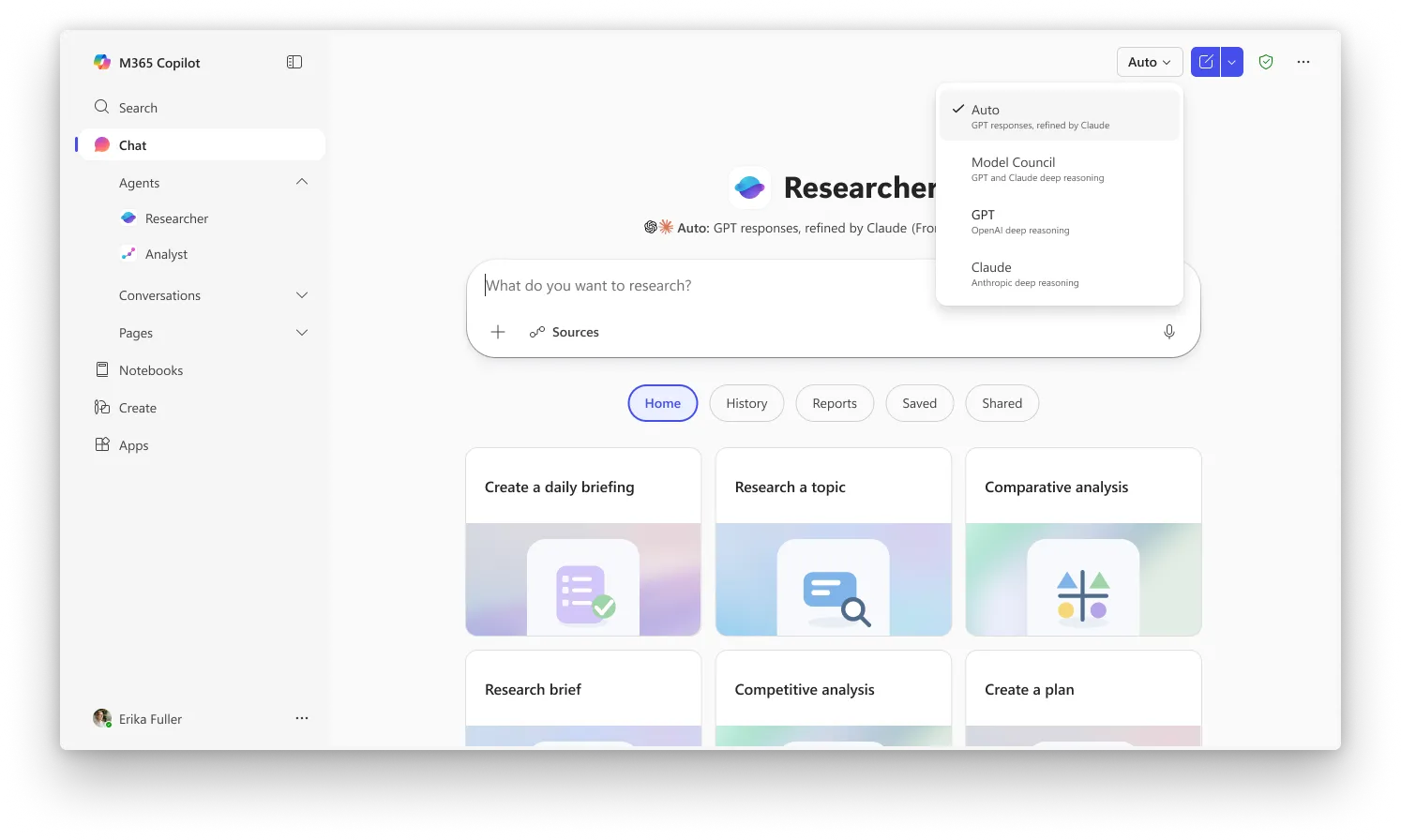
Critique is the default experience in Researcher whereas Council requires you to select “Model Council” from the picker to activate the side-by-side mode. Both features are currently available to users enrolled in Microsoft’s Frontier program, the early-access channel for Copilot’s newest capabilities. A Microsoft 365 Copilot license ($30/user/month) is required, but users also need to be enrolled in Frontier to access them.
OpenAI and Microsoft have a multibillion-dollar partnership, but Microsoft’s bet is that no single model stays on top for long, and that the real value is in the orchestration layer that routes tasks to whichever combination works best.
Daily Debrief Newsletter
Start every day with the top news stories right now, plus original features, a podcast, videos and more.