
In brief
- Anthropic released Claude Opus 4.8 on Thursday, just six weeks after Opus 4.7.
- The update comes with gains across software engineering, reasoning, and computer use benchmarks at the same $5/$25 per million input/output token price.
- Opus 4.8’s alignment scores are now comparable to Claude Mythos Preview, Anthropic’s restricted frontier model, with rates of deceptive or misuse-friendly behavior substantially lower than its predecessor.
Six weeks. That’s how long it took Anthropic to go from Opus 4.7 to Opus 4.8.
The new model is faster and smarter on benchmark tests, and ships with a suite of new features—but the price didn’t move: It’s $5 per million input tokens and $25 per million output tokens, same as before.
There’s also a fast mode that runs the same model at 2.5 times the speed for $10 input and a whopping $50 output per million. Anthropic says that rate is now three times cheaper than what fast mode cost on previous models, which is a nice way of saying it was much more expensive before.
SWE-bench Pro is probably the most important benchmark to watch and have an idea of how good this model is. It measures whether an AI can actually solve hard, multi-language software engineering problems drawn from real production codebases—scored as a percentage of problems passing.
On that test, Opus 4.8 hit 69.2%, up from 64.3% for Opus 4.7. OpenAI’s GPT-5.5 scored 58.6%, and Google’s Gemini 3.1 Pro trailed at 54.2%. For a model at the same price point, that’s a meaningful jump.
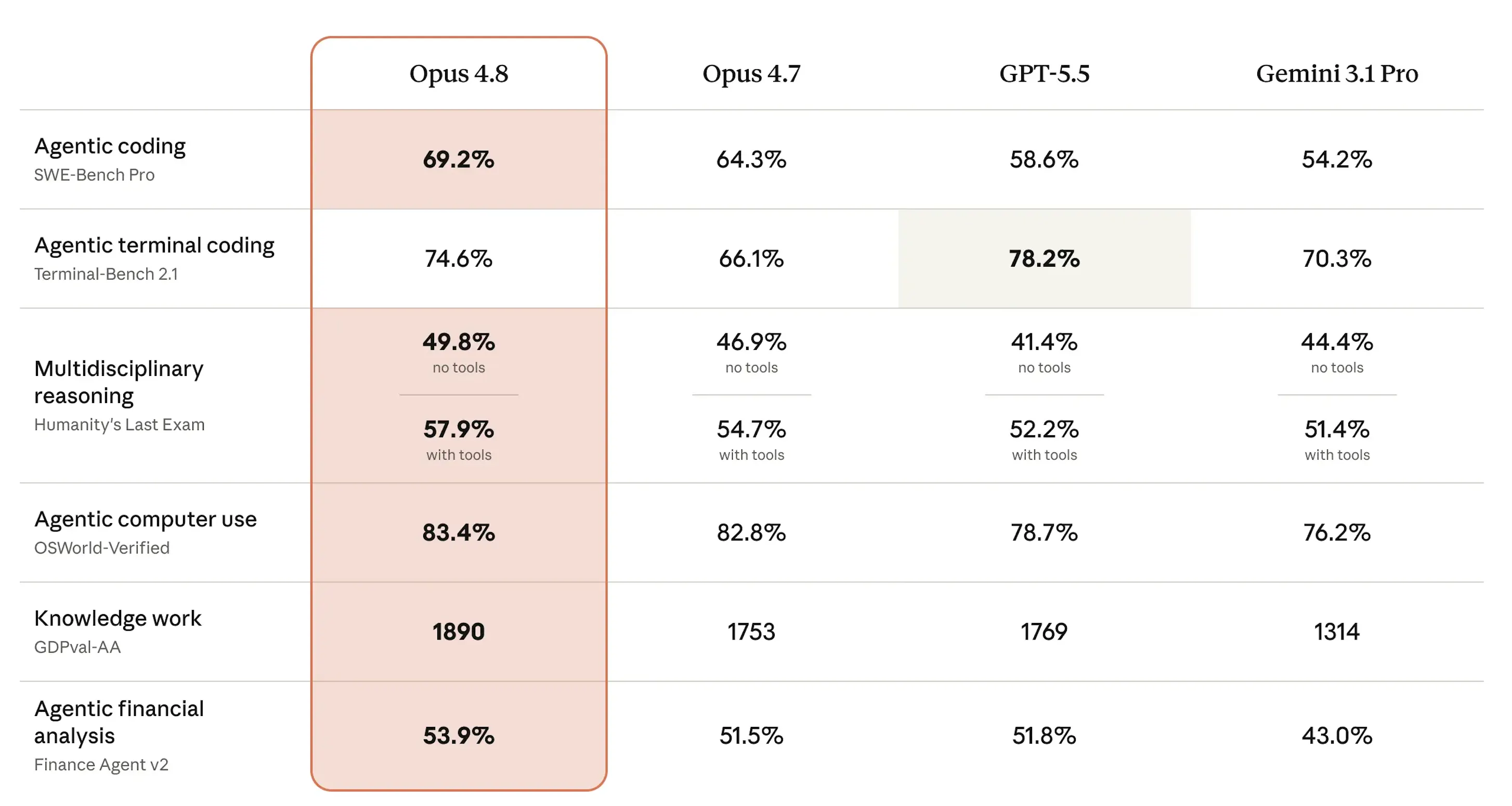
On Humanity’s Last Exam—expert-level questions across dozens of academic disciplines, scored as a percentage correct—Opus 4.8 reached 49.8% without tools and 57.9% with them, ahead of all three rivals. OSWorld-Verified, which tests real-world computer use tasks like navigating software UIs, came in at 83.4%, nudging past Opus 4.7’s score of 82.8%.
The one loss: Terminal-Bench 2.1, which measures AI performance on command-line tasks. GPT-5.5 leads at 78.2%, while Opus 4.8 scores 74.6%—better than Opus 4.7’s 66.1% and ahead of Gemini’s 70.3%, but second place is still ultimately losing.
Five ways to think
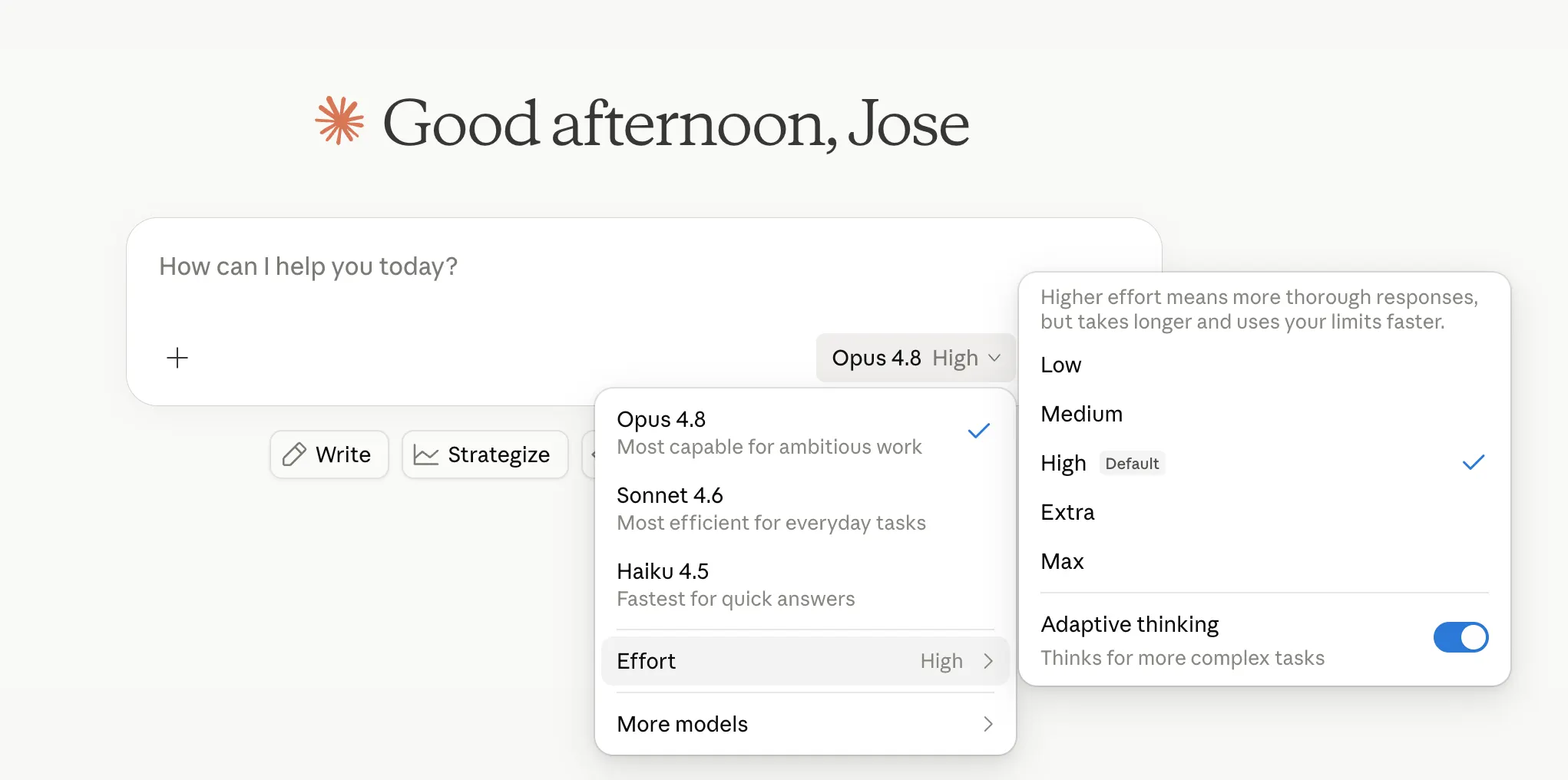
Anthropic is now letting users control how hard the model thinks. “High” is the default and handles most tasks well, while “Extra”—called “xhigh” inside Claude Code—spends more compute for harder problems. “Max” is the deep end. “Low” and “Medium” dedicate less tokens to the same task, saving some time in exchange for accuracy.
The effort control sits alongside the model selector in claude.ai and Cowork, available on all plans. Anthropic says default high uses roughly the same tokens as Opus 4.7’s default with better results—which is either impressive engineering or good messaging, and probably both.
It’s also important to remember that Anthropic’s new tokenizer for Opus uses more tokens per task. So Claude users are inevitably bound to burn a lot more money to get things done, should they choose Opus instead of Claude Sonnet—a less capable model, but probably good enough for everyday tasks and complex problems that don’t reach the level of frontier science or coding.
Rate limits in Claude Code were also raised to absorb the higher token spend that the Extra and Max settings produce.
Almost as safe as Claude Mythos
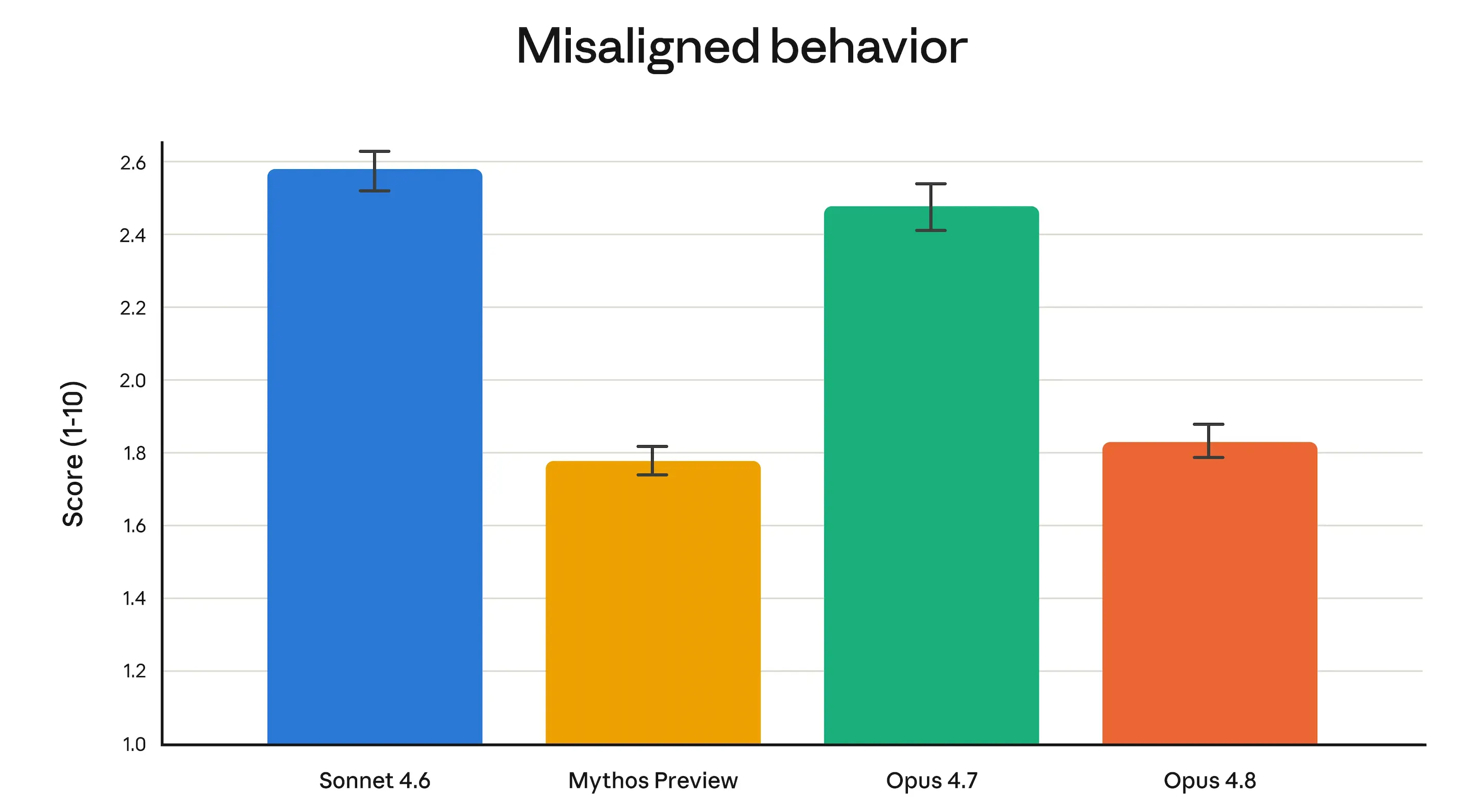
Anthropic’s alignment team said Opus 4.8 “reaches new highs on our measures of prosocial traits like supporting user autonomy and acting in the user’s best interest.” More concretely: deception rates and misuse-cooperation rates came in substantially lower than Opus 4.7, and comparable to Claude Mythos Preview—Anthropic’s most locked-down model.
Opus 4.8 is also four times less likely than 4.7 to let bugs in its own code slide past without flagging them.
That Mythos comparison deserves context. Mythos is a tier above Opus entirely—Anthropic describes it as “larger and more intelligent than our Opus models.” It currently exists only as a preview, accessible to a handful of vetted organizations doing cybersecurity work through Project Glasswing.
The U.K.’s AI Security Institute found it could autonomously complete “The Last Ones,” a 32-step corporate network attack simulation that usually takes human red teams 20 hours. That’s why it’s not yet for sale. Anthropic says stronger cyber safeguards are in progress, and expects to bring Mythos-class models to everyone “in the coming weeks.”
Also shipping today: dynamic workflows in Claude Code, in research preview. The feature lets Claude write its own orchestration scripts and spin up parallel subagents in a single session, verify their outputs, and report back—just like what Hermes has been doing for a while now.
Dynamic workflows are available for Enterprise, Team, and Max plan users, and Anthropic is upfront that they burn significantly more tokens than a standard Claude Code session.
The widening price gap
Anthropic’s $5/$25 pricing looks very different next to what China has been doing lately.
DeepSeek V4 Pro made its 75% discount permanent last week: $0.435 per million input tokens and $0.87 per million output tokens. Xiaomi MiMo V2.5 Pro runs at the same rates via providers like OpenRouter.
Anthropic’s fast mode costs $10 input and $50 output per million—more expensive than standard Opus 4.8 itself, and roughly 57 times more per output token than DeepSeek V4 Pro. Corporations have already spent millions of dollars in inference on American models. Go wild with Opus and your enterprise may reach millions of dollars pretty quickly.
Anthropic’s answer to the price gap is quality and safety. On SWE-bench Pro, Opus 4.8 beats both Chinese models. On alignment, neither comes close to Anthropic’s published benchmarks.
Those things matter in production environments where a model quietly cooperating with bad inputs is an actual risk—regulated industries, legal work, and anything where “it seemed fine” isn’t an acceptable post-incident report. For everyone else, the gap is hard to ignore.
We tested it
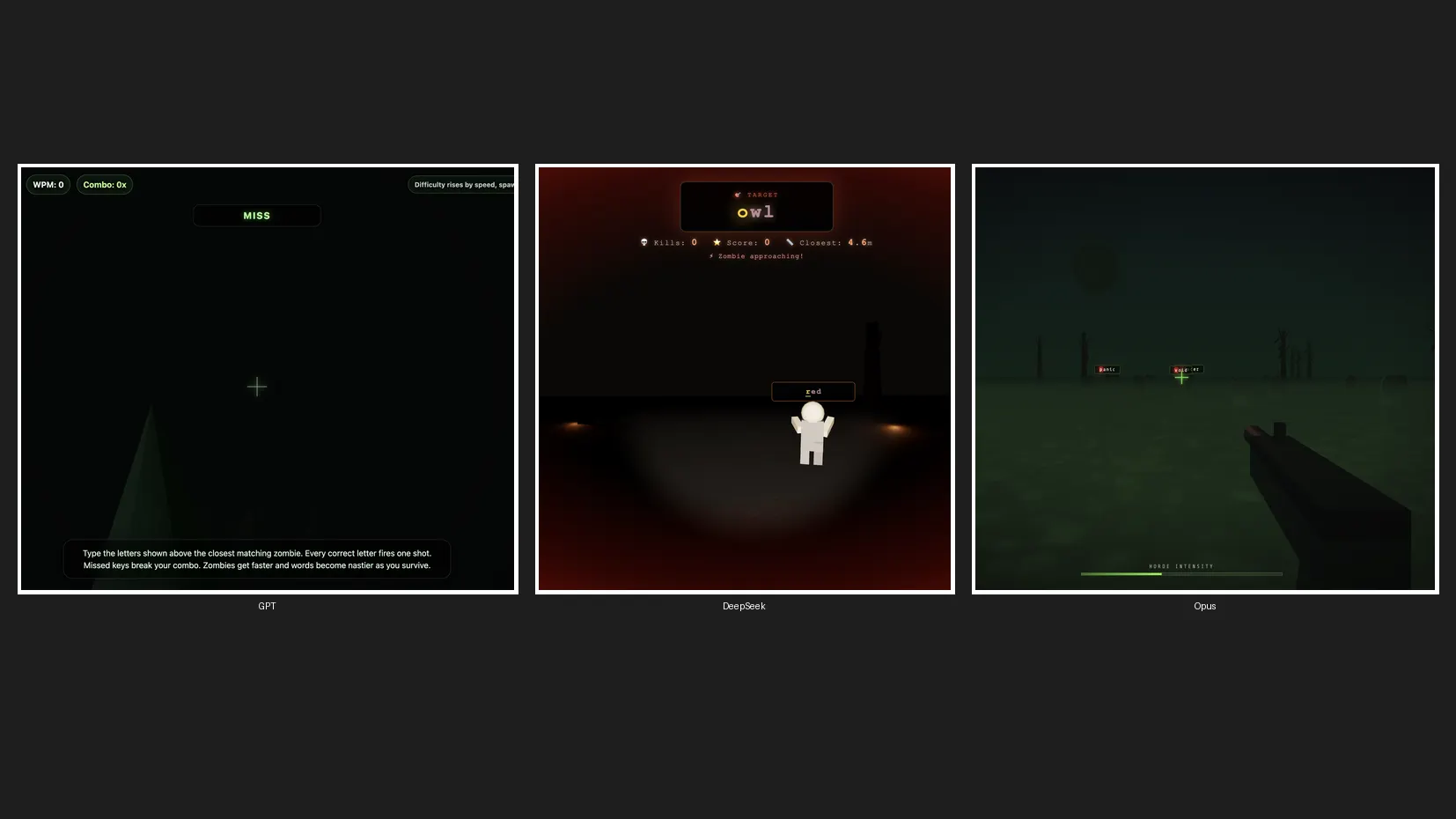
We ran a quick coding test to create a 3D zombie game to see how Claude Opus 4.8 stacks against ChatGPT and DeepSeek, arguably its most popular competitors from the U.S. and China. We set Opus 4.8 on default high, GPT-5.5 on high effort, and DeepSeek V4 Pro on high effort—three models, one prompt, no retries.
GPT-5.5 finished first. Its game had no zombie visuals and no sound effects. It was fast, sure, but it missed the brief entirely.
DeepSeek V4 Pro came in second with mouse movement, actual zombie characters, sound effects, solid mechanics, and a clean aesthetic. No complaints there.
Opus 4.8 took roughly three times as long as GPT-5.5, but delivered the best splash screen, the best zombie designs, the best game mechanics, and decent sound effects. It was the slowest, but the best output. Still, that’s probably not enough to justify using it over DeepSeek, given the cost gap.
All the games are available on our Itch.io Profile. GPT-5.5 generated Zombie Typing, Opus generated Typing Dead, and DeepSeek v4 Pro generated a game without a name that takes you right into the action. Let’s call it TypeSeek.
A full comparative review is coming. For now: Claude Opus 4.8 codes better than GPT-5.5 and Opus 4.7 for this kind of task, at the same price Anthropic has charged since 4.7. Developers who were already paying $5 per million tokens just got a better model for free.
Daily Debrief Newsletter
Start every day with the top news stories right now, plus original features, a podcast, videos and more.